
前章でも見てきたように、言語は文の集合体であり、さらに文は終端記号の集合体である。プログラミング言語における終端記号は三種類存在している。特殊な(短い)文字列で表現される演算子、あらかじめ決められた文字列で表現される予約語、そして特殊な文法の規定に従う定数や識別子などのユーザが定義する終端記号である。もちろんブランク文字やタプコードや改行文字のような空白文字も存在する。これらは、最近のプログラミング言語では、ただ単に終端記号を分割するものか、あるいはまったく意味がないものである。また、コメントもそれぞれのプログラミング言語の文法によって異なるが、空白文字と同様に、意味がないものとして扱われる。
本章では、コンパイラに与えられた無秩序な入力文字列から終端記号を取り出す作業、すなわち編集段階である字句解析を取り扱う。字句解析では通常、空白文字やコメントは無視される。また、演算子や予約語が認識され、内部表現一通常は小さな値をとる整定数一に置き換えられる。ユーザの定義した定数や識別子は適当なテーブルに保存され、IdentifierやConstantという一般的な表現と、その内容が保存されたテーブル上の位置とが次段に渡される。字句解析の問題は、次のような形式を持った実際の言語定義を用いて、模擬的に解決することができる。
statement
: 'I' 'F' condition 'T' 'H' 'E' 'N' statement
しかしながら、結果としての文法は矛盾を含まざるをえず、技術的には非常に非効率的である。
字句解析は、コンパイラの作業の中でも大部分を占めるものとなる。他のコンパイラの処理とはほとんど独立したものである字句解析を扱うことで、もっと適切な手法を用いることが可能となり、また同時に,我々が日常的に利用する文字セットを使用したプログラミング言語の記述についての情報を、1つのモジュール内に隠すことが可能となる。
我々はいかに文字列から終端記号を構成していくのであろうか?字句解析は有限状態オートマトンの理論のための伝統的なアプリケーションである。プログラミング言語の語彙表現の仕様から遷移図を作り出すのは簡単であり、漠然と遷移図に基づいて10時間前後の時間を費やせば、どのような仕様にも対処できるであろう。文字列、コメント、そして(浮動小数点)定数を大方その順番に処理しようとすると、通常汚らしいものになる。まず、図によって、遷移図として表現されたCスタイルのコメントを考えてみる。
遷移図では状態は番号の付いたノードとして表わされ、遷移は状態間の枝で表わされる。そしてこの枝にはその遷移をもたらす文字が付記されている。特徴的なことは、終端記号を検出しての遷移からの脱出は偶然のものであり、ある場合には次に続く文字を先読みしているし、ある場合にはそうではない。
遷移図は完全にきっちりと文法グラフに一致している。遷移図の枝は状態遷移を表わしているが、文法グラフのノードは状態変化を起こすための記号を含んでいる。両者の違いは、文法グラフが通常互いに別の文法グラフを呼び出すのに対し、遷移図ではそのようなことは仮定されないことである。
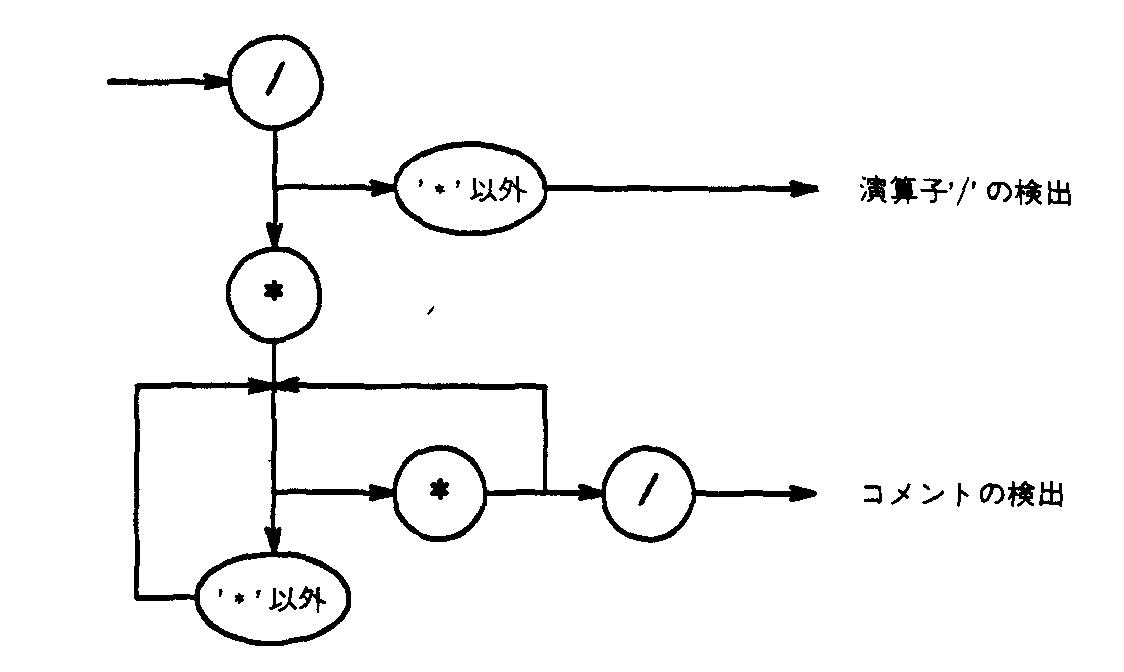
両者の比較を通じて、なぜ遷移図が字句解析のための方法として選ばれるかがわかるであろう。しかし、この方法そのものは間違いやすく、結果を修正しにくい。
もっと良い字句解析の問題の解決方法は、次のようなセオリーから直接引き出される。言語仕様を満足する有限状態オートマトンを表現する便利な方法が必要であり、また、その表現から適当なテーブルを作り出すコンパイラが必要であり、そしてこのテーブルによって有限状態オートマトンをシミュレートするインタプリタが必要となる。
このような目的に対して、lex[Les78bコと呼ばれるコンパイラが実際に作られている。lexはエディタのパターン(5)に似たパターンからなるテーブルを受け取り、パターンを満足する入力文字列を解析することのできるテーブル駆動型のCプログラムを作り出す.エディタの代用コマンドが示すように、バターンはある特定の文字列を認識するために非常に便利なものである。
パターンは有限状態オートマトンを実際に構築するための非常に便利な定義用言語である。それぞれのパターンに対して、入力内にそのパターンを満足する文字列が見つかった際に実行されるC言語の命令が作られる。簡単な翻訳用のアプリケーションでは、通常C言語の文は変更した文字列のコピーを標準出力に書き込むが、コンパイラでは、文字列に対して適当な符号化を行なったものを、字句解析関数を呼び出した関数に返さなくてはならない。
これから見ていくように、leXは本来非常に強力なツールであり、言語の認識に対して便利に使うことができる。しかし、私見ではあるが、1eXはユーザに対する親和性がきわめて悪い。エラー・メッセージは短く、しかも不明確である。また、leXに対してのコメント的な入力は、どう見ても煩わしいものである。さらに、leXを上手に使用しないと、巨大なプログラムを作成してしまう。しかし、それでもleXは字句解析のためには利用すべきツールである。というのも、もう一つの選択肢である字句解析関数の自力での作成は、非常に手間がかかってしまうからである。
本章の残りの部分では、大部分のコンパイラ・アプリケーションに対処するのに十分なleXの特徴について、詳細を示す。まずはじめに、もっとも頻繁に利用されるパターンのためのオペレーションについて、leXではパターンがどのように記述されるかについて、および識別子、文字列、コメントなどの標準的な言語の構成要素がどのようにパターンとして表現されるがについて、示す。ここでは大部分の可能性を示すのであり、その詳細を示すことはしない。
2.5節ではlexをプログラム生成ツールとして紹介し、2、3の、小さいものではあるが、ファイルの挿入、分割、単語の数え上げの完全なlexのプログラムを示す。我々のsampleCの実装については、sampleCのための完全な字句解析機構が示される2.7節でさらに紹介する。
edやそれに似たテキスト・エディタのユーザは、次のようなパターンの構成に十分慣れ親しんでいる。
パターンの最後の$は入力行の最後を示している(ただし改行文字そのものではない)。
特殊文字や空白に対しての適当なエスケープの規定とを合わせると、プログラミング言語の大部分の終端記号に対してのパターンが表現できる。1eXでは二つのエスケープの規定がある。
大部分の特殊文字は、1eXにおいては特殊な意味を持っている。もし特殊文字がその文字自身を表現しているのであれば、それは特殊な意味を失っているということである。特殊文字はキャラクタ・クラス内においては特殊な意味は持たない。空白は常になんらかの方法によって特殊な意味を失わせることを明確にするか、\によるエスケープ・シーケンスによって表現されなくてはならない。引用符内の引用符は、C言語と同様に\"で表わされる。
以下、例を挙げてsampleCのいくつかの終端記号に対するパターンを示す。演算子は単純に引用符で囲まれている。ここではバックスラッシュのコンベンションよりも引用符を使う。したがって演算子は、
"*" "--" "*="
のように示される。空白を認識するためのパターンも必要である。
[ \t\n]
定数は一つ以上の数字から成立している。
[O-9][O-9]*
識別子はC言語の規則による。すなわち、文字あるいはアンダースコアで始まり、その後に任意の個数の英文字、数字、アンダースコアが続く。
[A-Za-z_][A-Za-z0-9]*
次のパターンは1行内のコメントを扱おうとするものである.
"/*".*"*/"
コメントは/*で始まり、最初の*/で終る。これは複数行に拡張することもできる。
最後の二つのパターンは、edのユーザがよく知っているある制限を示している。それは、パターンは一致するものの中でもっとも長い入力の連続を表現している、ということである。定数や識別子の場合は、このパターンで得られるものは目的のものであろうが、コメントの場合は厳密には正しくない。もし、次のように記述した場合には何が起きるかという問題がある。
"<" "<="
つまり,最初の文字が同じである二つのパターンを記述した場合である.また,
"int" [a-z][a-z]*
のように、一方が他方の可能性のサブセットになっている場合も問題となる。このような暖味さについては次の節で扱う。
C言語やPascalスタイルのコメントや文字列をきちんと取り扱うためには、もう少しlexのパターンの特徴を紹介しなくてはならない。ちょうどegrep (6)のように、丸カッコはパターン内でのグループ分けを行なうことができ、また|は別の候補を示し、十はその要素の一回以上の連続を示し、?はその要素が存在しないか、あるいは一回だけ発生することを示している。最後の二つの機能を使うと、先に示したパターンのうちのいくつかを書き換えることができる。たとえば、整定数は次のようなパターンで解析される。
[0-9]+
Pascalスタイルのコメントのように、1文字をデリミタとして使用する終端記号は扱いやすいものである。
"{"[^}]*"}"
別候補を示す機能を使えば、PascalやC言語の文字列のように、デリミタが文字列内に現われる際には、そのデリミタを二重にするかエスケープしなければならない場合にも、簡単に表現できる。
\'([^'\n]|\'\')+\' \"([^"\n]|\\["\n])*\"
ここで、Pascalスタイルの文字列では複数行にまたがるものには拡張されていないこと、および少なくとも1文字は含まなくてはならなくなっていることに注意していただきたい。C言語での文字列の場合には、改行が\でエスケープされていれば複数行にまたがらせることも可能であり、またエスケープされた引用符を含むことも可能であり、さらに内容が空でも良い。デリミタとして連続した文字を使っている場合、たとえば/*と*/で囲まれたCスタイルのコメントや、(*と*)で囲まれたPascalスタイルのコメントの場合、必要なパターンはきわめて複雑なものになる。基本的な考え方は、いったん開始のデリミタが解釈されたなら、終了のデリミタを許可しないことである。しかし残念なことに、これはパターンを列挙するしか実現の方法がない。次のような、Cスタイルのコメントを解釈するためのパターンの案について考えてみる。
"/*""/"*([^*/]|[^*]"/"|"*"[^/])*"*"*"*/"
ここではO個以上の/が開始のデリミタの直後に続くことが可能であり、また終了のデリミタの前にO個以上の*が存在することが可能である。このようにして、特殊な場合にも対処が可能である。
もっといろいろなleXのパターンがある。繰返しは、たとえば次のような表記を用いた範囲を満足するところで終了する。
[a-z][a-z0-9]{0,7}
これは小文字で始まり、Oから7の英文字、数字がそれに続くという識別子を表現している。パターンには、その右側にある特定のコンテクストが続く場合にのみ解釈されるものもある。
この右側のコンテクスト自身は、そのパターンでは表現されない。右側のコンテクストは、次のような/で表現される。
-0[xX]/[0-9a-f]+
このパターンは、C言語における負の16進数のための符号と、基底を示すprefixを表現しているが、定数部の数字そのものは含まれてはいない。パターンはある初期状態の後に続くので、これによって同じパターン表現の中から一つを動的に選択することが可能となる。非常に有能な(そして注意深い)プログラマであれば、lexによって作成されたオートマトンのために用いられる入力、出力、あるいはバッファ管理の関数にまでも変更を与えることが可能である。勤勉な、想像力に富む読者には、オリジナルの出版物[Les78b]を参照することをお勧めする。
lexのパターンはきわめて曖昧な傾向がある。lexでは、分類を行なうために、次の二つの規則が用いられる。
この二つの規則は、欠点というよりもむしろ利点である。最初の規則は、次のようなパターン、
int [a-z]+
によってintegerが正確に(二番目のパターンの例として)認識され、最初のintとしては認識されないという利点を示す。二番目の規則によって、二番目のパターンではなく、パターンintが入力から文字列intを解釈するための一般的なパターンとなる。
ここで示したように、一番目の曖味さのない規則は、注意深く使わないと失敗してしまう。しかし、二番目の規則は、もっと一般的な、たとえば識別子を解釈するためのパターンが、選択的に例外を取り去ってゆくバターンが続いた最後に位置するような構成を実現するために役立つ。
次のような解釈上の問題点を考えてみよう:ドイツ語のテキストを英語用のキーボードを使用して打つ場合、ウムラウト文字はae、oe、ueなどと表わされる。ドキュメントをtroffやnroffに与えて、たとえばmsマクロ・パッケージを用いて処理をさせる場合,その処理に先立って、これらの文字の組合せをすべて\*:aや\*:o。のように,mSマクロにおける文字列\*:という先行文字列に置換する必要がある。しかし、ueパターンは、Quelle(ドイツ語で「泉」の意味)やeventuell(ドイツ語で「あるいは」の意味)のように、ウムラウトに置換されないものの中でも、ueの文字の組合せとして解釈されてしまう。したがって、これらの特殊な場合を、一般的な組合せ表現の前に取り去ることが必要となる。
[Qq]ue ntue ue
曖昧なパターンのリストであっても、lexの入力として受け入れられるので、もしもっと特殊な場合が存在するのであれば、そのパターンを次々に挿入するだけで良い。
入力順序の違いは、yaccでのreduce/reduce conflictsを誘発してしまう。yaccにおいてはコンフリクトを頻繁に生じるために、この問題はlexにおいて非常に重要となる。残念なことに、これはたびたびパターンの非論理的な配置を強いることになり、パターンの順序は制御構造のようなものとなってしまう。
leXの入力は、%%で始まる行で分割された三つの部分から構成される。
first part
%%
pattern action
...
%%
third part
最初の部分は存在しなくてもかまわない。ここでは1eXの内部で使用されるテーブルの大きさを指定したり、2.7節に示すようなテキストの置換のための定義を行なったり、先頭が%{で始まる行から%}で始まる行までの間で(広域的な)C言語のコードを置いたりする。もし、この一番目のleXに対しての記述部分が存在しないとしても、一番目の部分と二番目の部分の間の%%を省略することはできない。
三番目の記述部分と、二番目の部分と三番目の部分との間の%%は省略可能である。この部分では、そのまま使用されるC言語のコードを記述する。通常ここには、二番目の部分で使用される(局所的な)関数が記述される。
記述の第二のパートは、パターンのテーブルとアクションから成立している。このパートの記述は、完全に1行単位で処理が行なわれる。パターンは行頭から始まり、最初のエスケープされていない空白まで続く。その後、任意個の空白に続いて、そのパターンによって起動されるアクションが記述される。アクションは一つのC言語の文が、一対のブレース({})によって囲まれたいくつかの文である。アクションがパー(|)で記述されている場合には、現在のパターンが次のパターンのアクションを使用することを示す。
lexの入力そのものにはコメントを記述することはできない。しかし、ブレース内にC言語の通常のコメントとして記述することは可能である。
以上のテーブルの記述から、lexはファイルlex.yy.c内にC言語の関数yylex()を作成する。この関数がプログラムにリンクされ、呼び出されると、与えられたパターンの表現の中で一致する最長のものが得られるまで、標準入力が読み込まれる。続いてパターンによって起動されたアクションが実行される。このアクションがretun文を含んでいる場合には、yylex()は自分自身を呼び出した関数に戻る。この時、文中で指定されていれば、ある関数値を返す。
leXは、ユーザによって記述されたバターンに対して、それ以外の解析不可能な入力文字をすべて標準出力にコピーすることを行なうという、デフォルトのパターンとアクションを加える。
次のlexのプログラムは、入力からすべての大文字を消去するものである。
%{
/*
* remove upper case letters
*/
%}
%%
[A-Z]+
このプログラムがファイルexuc.lに書かれていたとすると、次のようなコマンドで実行可能なプログラムexucが作成される。(7)
lex exuc.l cc lex.yy.c -ll -o exuc
-llによってlexライブラリが参照される。このライブラリはyylex()を一回だけ呼び出すデフォルトのmain()関数を含んでいる。このライブラリは、lexによって作成されたyylex()関数をリンクする際には常に指定されなければならない。
もっと役に立つアクションにするためには、パターンによって解釈された入力文字列を直接操作できることが必要になる。文字型のベクタであるyytext[]は、この文字列を'\0'で終端された形で含み、整数型の変数yylengはStrlen(yytext)の値を持っている。また、整数型変数yylinenoは現在の入力ファイル上での行番号を保持している。次に、いくつかのプログラムを見てみよう。(8)
%{
/*
* line numbering
*/
%}
%%
\n ECHO;
^.* printf("%d\t%s", yylineno, yytext);
この最初のプログラムは標準入力を出力するものである。ただし、空白でない行の行頭には、その行の行番号とタプ文字を先行させる。ECHOは、lexによって作成されたCプログラムの中で定義されるyyteXt[]を出力するためのプログラムである。
空白行に対しても行番号を付加する場合には、次のプログラムが使用される。
%{
/*
* line numbering
*/
%}
%%
^.*\n printf("%d\t%s", yylineno-1, yytext);
ここでは改行コードがパターンの一部として解釈されているので、アクションに制御が移った時点では、yy1inenoは加算され、次の行を示している。
次のプログラムは、私のお気に入りのユーティリティである。
%{
/*
* word count
*/
int nchar, nword, nline;
%}
%%
\n ++ nchar, ++ nline;
[^ \t\n] ++ nword, nchar += yyleng;
. ++ nchar;
%%
main()
{
yylex();
printf("%d\t%d\t%d\n", nchar, nword, nline);
}
この例では、lexの三番目のパートが用いられている。ここでは独自のmain()関数が定義され、このmain()関数ではyy1ex()の実行中に収集された統計が表示される。次の例は、もう少し大きな問題の典型例であり、特殊なアタションーここではファイルの挿入一が、パターンが解釈された場合に実行されるものである。ほとんどの入力は,ただ単に通過するだけである。似たようなアプリケーションとしては、印刷プログラムにおいてある特定の単語を装飾するもの、または目次の収集を行なうものなどが挙げられる。
%{
/*
* .so filename file inclusion
*/
#include <ctype.h>
#include <stdio.h>
static include();
%}
%%
^".so.*\n" { yytext[yyleng-1] = '\0'; include(yytext+3); }
%%
static include(s)
char *s;
{
FILE *fp;
int i;
while (*s && isspace(*s))
++s;
if (fp = fopen(s, "r"))
{
while ((i = getc(fp)) != EOF)
output(i);
fclose(fp);
}
else
perror(s);
}
outputo (9)は、lexがすべての出力を書き出すために用いる関数である。このプログラムは1レベルのみのファイルの挿入を行なうものである。
最後の例は、入力で指定したファイルに書込みを行なうものである。これは一種のsplitユーティリティである。
%{
/*
* .di filename file splittiong
*/
#include <ctype.h>
#include <stdio.h>
static divert();
%}
%%
^".di.*\n" { yytext[yyleng-1] = '\0'; divert(yytext+3); }
%%
static divert(s)
char *s;
{
while (*s && isspace(*s))
++s;
if (! freopen(s, "w", stdout))
perror(s);
}
この例は、sedやawkなどの出力ファイル数の限定されているようなツールでは対処が困難である。1eXは複雑なコンテクストの中からファイル名を取り出すことができるので、この解決法は最初からC言語で記述したものよりも変更がずっと容易である。
Linux, cygwinでは、
flex exuc.l gcc lex.yy.c -lfl -o exuc
となる。
flexでは、yylinenoが予約変数として用意されていないため、
%{
/*
* line numbering
*/
int yylineno;
%}
%%
\n ++yylineno, ECHO;
^.* printf("%d\t%s", yylineno+1, yytext);
のように修正する必要がある。
yylex()をコンパイラの字句解析部として使用するためには、整数値を返す関数として設計しなければならない。この関数が呼び出されるごとに次の終端記号が入力から読み込まれ、解析され、関数値として返される。おのおののパターンは一っ以上の終端記号を認識するように設計され、起動されるアクションには関数値を作り出すためのreturn文が含まれている.たとえある文字が終端記号に含まれるものでなくても、あるいはただ単に無視されるべきものであったとしても、それらを含めて,すべての入力文字が認識されるようにしなくてはならない。というのも、yylex()はパターンで定義されていない文字列を表示してしまうからである。
このような関数をテストするのは困難であろう一というのも、関数値は数値であり、通常それはあまり覚えやすいものではないからである。しかし、C言語のプログラミング上のテクニックはテストを行なうために非常に役に立つ。(10)デバッグのために、次のような特殊な構造をlexのプログラムに与えてみる。
%{
#include <assert.h>
#define token(x) (int)"x"
main()
{
char *p;
assert(sizeof(int) >= sizeof(char *));
while (p = (char *)yytext())
printf("%s is \"%s\"\n", p, yytext);
}
%}
%%
pattern return token(MNEMONIC);
このsamp1eCの例で示すように、この方法によると、条件付きではあるが、常にテスト用にコンパイルされるような字句解析関数を構築することが可能である。yylex()を呼び出した側はMNEMONICという値をyylex()の結果として、しかも表示可能な形式で受け取る。この簡単なmain()関数では、デバッグのために、入力されたテキストであるyytextと、解析され関数値として戻された表現とをともに表示する。
ファイルの終りを検出した場合には、yy1ex()はゼロを返すものとして扱われている。lexはこの状況を内部的に作り出すようにyylex()関数を生成する。したがってmain()関数はyylex()がゼロを返した時に終了するように書かれている。
最後にアドバイスを一つ付け加えておく。プログラミング言語の予約語をパターンとして記述することは非常に簡単である。しかし残念なことに、予約語を直接示すパターンのような長いリストは、leXによって生成されるプログラムのサイズを非常に大きくしてしまう、予約語と識別子を同じ一つのパターンで見つけ出し、その結果を簡単なC言語の関数を使ってふるい分ける方がずっと効率的である。この問題に関しての標準的な解決手法については、次の節で述べる。
sampleCに対するyaccの記述から、どの終端記号がコンパイラのために字句解析ルーチンによって検出されなければならないかがわかる。yylex()は%token文で指定されたすべての記号と、直接特殊な意味を喪失しているすべての1文字からなる終端記号を検出することが必要である。前節で示したデバッグのための手法を使うことで、さまざまな終端記号に対する解析結果として得られる正確な関数値を知る必要はなくなる。
我々の作成するコンパイラに先立って、C言語のプリプロセッサを走らせるため、パターンはそれほどむずかしいものとはならない。C言語のプリプロセッサはコメントを消去するであろうし、#defineや#includeや条件付きのコンパイルをsampleCでも可能にするであろう。
完全な最終的な字句解析部を以下に示す。'DEBUGはテストのためにコンパイルを行なう際に定義する。したがって、以下のファイルの中のある行は、現在では無視されている。それに関しては、第3章の言語解析プログラムの統合の際に述べる。
%{
/*
* sample c -- lexical analysis
*/
#ifdef DEBUG /* debugging version - if assert ok */
# include <assert.h>
main()
{
char *p;
assert(sizeof(int) >= sizeof(char *));
while (p = (char *)yylex())
printf("%-10.10s is \"%s\"\n", p, yytext);
}
s_lookup() {}
int yynerrs = 0;
# define token(x) (int)"x"
#else !DEBUG /* production version */
# include "y.tab.h"
# define token(x) x
#endif DEBUG
#define END(v) (v-1 + sizeof v / sizeof v[0])
static int screen();
%}
letter [a-zA-X_]
digit [0-9]
letter_or_digit [a-zA-Z_0-9]
white_space [ \t\n]
blank [ \t]
other
%%
^"#"{blank}*{digit}+({blank}+.*)?\n yymark();
">=" return token(GE);
"<=" return token(LE);
"==" return token(EQ);
"!=" return token(NE);
"+=" return token(PE);
"-=" return token(ME);
"*=" return token(TE);
"/=" return token(DE);
"%=" return token(PP);
"++" return token(MM);
"--" return token(GE);
{letter}{letter_or_digit}* return screen();
{digit}+ {
s_lookup(token(Constant));
return token(Constants);
}
{white_space}+
{other} return token(yytext[0]);
%%
/*
* reserved word screener
*/
static struct rwtable { /* reserved word table */
char *rw_name; /* representation */
int rw_yylex; /* ylex() value */
} rwtable[] = { /* sorted */
"break", token(BREAK),
"continue", token(CONTINUE),
"else", token(ELSE),
"if", token(IF),
"int", token(INT),
"return", token(RETURN),
"while", token(WHILE)
};
static int screen()
{
struct rwtable *low = rwtable,
*high = END(rwtable),
*mid;
int c;
while (low <= high)
{
mid = low + (high - low)/2;
if ((c = strcmp(mid->rw_name, yytext)) == 0)
return mid->rw_yylex;
else if (c < 0)
low = mid + 1;
else
high = mid -1;
}
s_lookup(token(Identifier));
return token(Identifier);
}
に存在したとすると,テストのための字句解析機構のコンパイルは次のように行なわれる。
lex samplec.l cc -DDEBUG lex.yy.c -ll -o lexi
終端記号が認識されることを確認するために、いくつかのテストをこの字句解析機構に対して行なってみよう。もっとも簡単な、しかし完全なプログラムは、以下に示すものである。
main() {}
このプログラムに対して、字句解析機構は以下のような出力を示す。
Identifier is "main"
yytext[0] is "("
yytext[0] is ")"
yytext[0] is "{"
yytext[0] is "}"
我々は1文字の演算子を認識するために、また同時に、すべての不正な入力を検出し、通知するために、非常に単純な手法を用いている。つまり、どのようなパターンでも検出できない場合、その文字そのものの値をyylex()の値として返している。この方法を用いることで、コンパクトな字句解析部を作り出すことができ、また字句解析後に入力エラーをもっと系統的に扱うことが可能となる。
この字句解析機構の別の特徴も示してみよう。leXはパターン内での簡単なテキストの置換機能を持っている。
name replacement
の形式を持った行がleXの記述の第1のパートに存在する場合、この行はある名前に対するテキストの置換を定義する。この名前はパターン内では、
{name}
の形式で記述され、replacementに交換される。この機能はしばしば、パターンをより透過的、かつ覚えやすいものにする目的で使用される.最初のパターンは、
# linenumber filename
という形式を持ったCのプリプロセッサによって作成されるファイルの挿入や、条件付きコンパイルの際の位置の表示を行なっている行を扱うものである。第3章で示されるように、yymark()はエラー・メッセージに関する情報を収集するための関数である。
ここでは、識別子として認識された終端記号の特殊な形式としての予約語を認識する目的で、簡単なバイナリ・サーチの関数screen()を使っている。このscreen()が、ふるい分けの問題に対する解決のための一例である。ここで、tokenを使った手法が予約語のテーブルでどのように使われているかに注意していただきたい。
s_lookup()は記号テーブル管理のための関数であり、第5章の最初で示されている。
ANSI Cの処理系では、オリジナルのままでは期待した出力が得られないため、#define文の定義、#else、#endifiの表現を以下のように修正した。
# define token(x) (int)#x #else /* !DEBUG production version */ # include "y.tab.h" # define token(x) x #endif /* DEBUG */
また、otherパターンが原文と異なっており、
other .
と.が必要である。
あなたの好きなプログラミング言語で書かれたプログラムを読んで、そのプログラムの中の予約語をすべて解釈し、すべて大文字に変換して出力するleXプログラムを作成せよ。そのほかの大文字はすべて小文字に変換せよ。
ヒント:予約語を解釈するためにはscreen()(2.7節参照)のような関数を用いよ。
あなたの好きなプログラミング言語で書かれたプログラムを読んで、そのプログラムの中の識別子のクロス・リファレンス・テーブルを作成せよ。
ヒント:lexプログラムが識別子を認識したら、適当なCプログラムを使用して、まず、これは最終的には無視されるものであるが,言語の予約語のテーブルとの照合を行ない、次にそれまでに認識された識別子のテーブルとの照合を行なう.新たな識別子は後者のリストに加えられる。それぞれのリストのエントリは、yylinenoから得られる値を記録したクロス・リファレンス要素の連鎖の先頭である。yy1ex()の終了後、クロス・リファレシス・テーブルが出力される。