この章では、いくつかの事柄を統合している。すなわち、yacc入力される文法、構文解析プログラムlexの仕様、さらに簡単な記号テーブルの機能を結び付け、言語認識プログラムを作成する。ここでの例で示されるように、このような言語認識は、整ったプリンタ出力を行なうプログラムなどに利用することができる。
まず最初に、yaccが文法を入力とし、ファイルy.tab.cに出力し、またファイルy.outputにその解説を出力するパーサの働きを理解しなければならない。この背景を明確にするために、3.2節では、samp1eCの言語認識においてそれらが実際にどのように結び付けられるかを示す。
ここでは、認識プログラムを起動するためのmain()プログラムと、入力に誤りがあった場合にパーサから呼ばれるyyerror()が示される。3.3節では、コンパイラの前にCプリプロセッサを呼ぶことができるような高機能のmain()を示すまでには至らない。また、パーサヘの入力におけるエラー位置を示すための一般的なyyerror()関数を示すに留める。
残念ながら、文法がいつも言語デザイナーの意図した通りになっているとは限らない。そこで3.4節では、言語認識におけるバグの対処の仕方を述べる。そして、ファイルy.outputとya?tのデバッグ・オプションを結び付けることにより、文法における誤りを見つける有効な方法を示す。
この章の最後には、samp1eCのフォーマッタを示す。このようなプログラムを実際に実行するためには、その前に、終端記号に関する情報を構文解析プログラムがらパーサに渡すための問題を解決しなければならない。そこで3.5節では、yaccがどのように実行されるかを示し、さらに、簡単な電卓の例によってyaccの柔軟性を示す。
1.4節では、文法がyaccによってどのように解析されるかを説明した。解析は、任意の終端記号が受け入れられるかどうかを、すべての規則にわたって同時に行なうことになる。しかし、もしyaccに対して実際の入力を行なうとすると、実際には多少単純なものとなる。なぜなら、膨大なすべての可能性を同時に調べるのではなく、yaccは入力によって選ばれた状態にのみ遷移するからである。そして、その結果は言語認識のための一つの機構、つまり、パーサあるいはシンタックス解析プログラムとならわばならない。
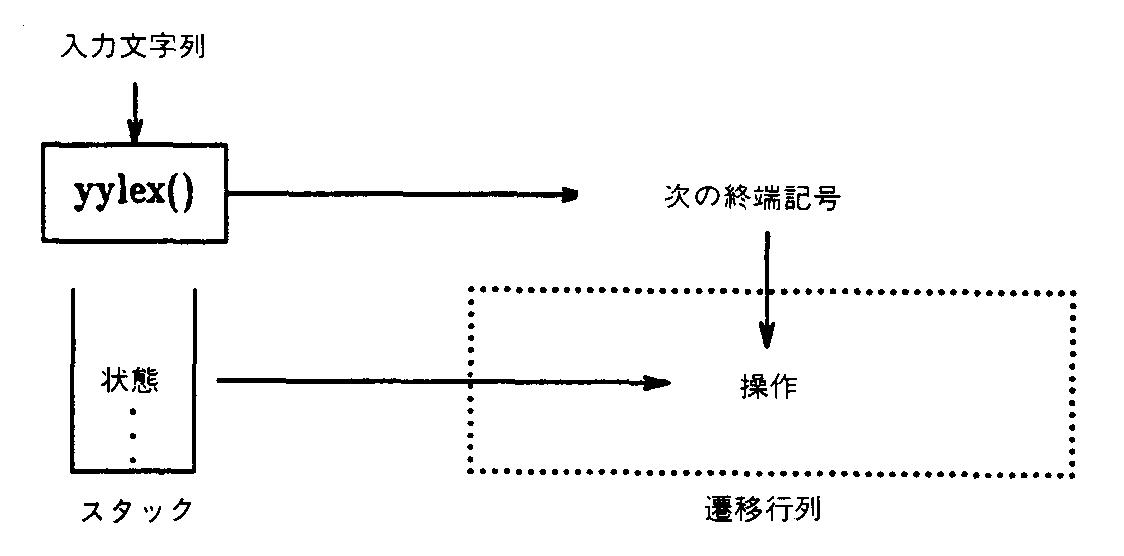
yaccは文法を解析し、パーサを生成する。パーサは、現在の状態を記憶するための大きなスタック、現在の状態と次の入力記号のすべての可能な組合せに対して新しい状態を作り出す遷移行列、認識のある時点において実行されるユーザ定義アクション、および、実際に許される実行を行なう最終的な翻訳機からなる自動装置、すなわちスタック・マシンである。この結果は、標準入力を読み込むための、構文解析の関数yylex()を繰り返し呼ぶ関数yyparse()としてまとめられる。yyparse()は、入力ファイルに“文”があったかどうかを示すために、1または0を返す。
パーサの機能を図化すると、次のようになる。
yylex()を呼んだ時に必要に応じて作られる、現在の状態、すなわちスタックの一番上にある“状態”と次の終端記号とによって、一つの操作が遷移行列から選び出される。ファイルy.outputは、次の可能な終端記号と状態のための遷移行列の内容を示している。遷移行列中には五つのタイプの操作がある。
前項で示されたように、本来、reduceの操作は、次の終端記号より前に用いられる非終端記号を生成するものである。gotoはこの非終端記号に対するshiftの操作である。shiftは次の終端記号を使ったり捨てたりするものであるが、gotoは非終端記号を使い、次の終端記号を後のshift操作に委ねる。それ以外はgotoとshiftは基本的に同じである。つまり、新しい状態がスタックに積まれ、やがて“現在の状態”となる。操作の働きを理解するため、第1章に出てきた簡単な文法の例をもう一度見てみよう。
expression
: expression '-' IDENTIFIER
| IDENTIFIER
第1章では、この文法からyaccが作るファイルy.outputを示した。ここで、このファイルがパーサを完全に示していることを確かめてみよう。パーサは、スタック上の現在の状態として、state 0から始める。
state 0
$accept : _expression $end
IDENTIFIER shift 2
. error
expression goto 1
もし、次の終端記号がIDENTIF1ERであったら、次にshiftの操作が行なわれる。すなわち、記号を受け入れ、新しい状態state2をスタックに積む.これ以外のいかなる入力記号もerrorとみなされる。
state 2
expression : IDENTIFIER_ (2)
. reduce 2
新しい次の終端記号に関係なく、reduceの操作としてfomulation2を用いる。formulatIon2は記号(IDENTIFIER)からなっているので、スタックから次の状態をポップすることになる。そしてstate 0がもう一度スタックの一番上に現われる。
reduceの操作により非終端記号としてexpressionが生成され,state Oの命令によりgoto state1が実行されることになる.それゆえ,もし次の終端記号があったとしても,ここでは考慮されないことに注意しなくてはならない.
state 1
$accept : expression_$end
expression : expression_- IDENTIFIER
$end accept
- shift 3
. error
state1において、入力の最初のIDENTIFIERの後の記号を考えた。この段階では、$end、すなわち入力の終わり、あるいは一の演算子が次に来ることになる。$endは、このパーサがIDENTIFIERを文として認識したことを意味するacceptの操作へと続く。ここで説明したステップは、より長い文に対するy.outputにおけるパーサの働きを理解する助けとなるであろう。
ここにおいて、一つの問題が残っている。yy1ex()は、yyparse()が次の終端記号の値としていかなる値を取るかを、どのように知るのであろうか? 一つの自然なやり方としては、その文字セットの値を用いて、終端記号として1文字で表わす方法である。たとえば、C言語の定数'X'をyaccのための文法における終端記号'X'で表わすようにする。しかし、yaccの%tokenによって導入される一つの終端記号の名前に対して、yyparse()とyylex()は、同じ整数の値を用いなければならない。そしてこの値は、1文字で他のものと区別されねばならない。
yaccは適当な値を決める手助けをしてくれる。次のコマンド、
yacc -d grammar.y
は、%tokenによって導入されるおのおのの名前に対して、C言語のプリプロセッサの文である#define一つを持つファイルy.tab.hを作成する。(12)それぞれの名前に割り当てられるのは、257から始まる整数の定数となる。
ファイルy.tab.hは、同じくyaccによって作成され、関数yyparse()を含むy.tab.cにすでに現われている。それゆえ、構文解析関数yylex()に対しても、C言語のプリプロセッサの文の#inc1udeを用いてy.tab.hを取り込むことにより、一つの終端記号に対して同じ値を用いることができることになる。
しかしこのために、終端記号のための文法で使われる名前や、%tokenによって導入される名前は、C言語の予約語とすることができない。構文解析関数yylex()は、自分で作ることも、あるいは第2章で示したように、1exによって生成することも可能である。
1.6節において、yaccに適合する形でsampleCを示した。それがファイルsamplec.yに定義されているとする。2.7節では、samp1eCの終端記号のための構文解析を含むsamplec.lを示した。したがって、これら二つの関数を結合して、sampleCのパーサを作ることが可能となる。
もし、構文解析のためのファイルをコンパイルする時にDEBUGを定義しなければ、samplec.lにおける次のCプリプロセッサの文、
#include "y.tab.h" #define token(x) x
は意味を持つことになる。第一の文により、yaccによって作られたy.tab.hにおける終端記号の値の定義がyylex()のコンパイルにおいて用いられる。また、第二の文により、構文解析のプログラムの、一つのデバッグ法が禁止される。デバッグにおいては,
#define token(x) int "x"
とすることにより、プリント可能なC言語の文字列として終端記号の名前を返すことができ、y.tab.hに定義されているそれらの名前に対する値を返すことが可能となる。
構文解析プログラムにおける最後のパターンは、
{other} return token(yytext[0]);
で、認識されていないすべての1文字の終端記号に対する値を返す役目をしている。このパターンは、1文字(文字あるいは数字)が前に出てきたパターンにより、IdentifierあるいはConstantとして認識されるようにするため、一番最後に置かれる。
次のコマンドにより、認識のためのプログラムが作られる。
lex samplec.l yacc -d samplec.y cc lex.yy.c y.tab.c -ll
上記のようにコンパイルを行なうと、main()のルーチンをlexのライブラリから持ってくるため、このmain()は、第2章で述べたようにyylex()を一度呼ぶだけで、パーサであるyyparse()はまったく呼ばない。そのため、次のようなmain()のルーチンを作成する必要がある。
main()
{
yyparse();
}
yaccのユーザが用意しなければならない、もう一つのルーチンがある。パーサが遷移行列におけるerrorの操作を行なう場合には、入力ファイルに文法誤りがあることになる。この場合、この時点でエラー・メッセージが出力されなければならない。そこで、yyparse()は次のサブルーチン・コールを行なう。
yyerror("syntax error");
たとえば、エラーが起こった入力位置を示すことができるようなyyerror()を作ることも、ユーザの責任において自由である。もっとも簡単なルーチンとして、次のような例が挙げられる。
#include <stdio.h>
yyerror(s)
char *s;
{
fputs(s, stderr), putc('\n', stderr);
}
ここで、エラーの数を数えておく必要はない。エラーの数はyyparse()によって自動的にカウントされ、整数の変数yynerrsに保存される。
以上の二つのファイルがextra.cにあるとすると、次のコマンドによってコンパイルが可能となる。
cc extra.c lex.yy.o y.tab.o -ll
これにより、認識を行なうプログラムがa.outとして作成され、次のような形で実行を行なうことができる。
a.out
main() { }
^D
これを実行しても何も起こらないが、そうあるべきものである。つまり、
main() { }
は、非常に小さな正しいsampleCのプログラムである、ということを意味している。ここでの認識プログラムは、入力が正しいプログラムである時、何も出力しない。正しくなければ、ただSyntax errorと出力するであろう。
前節で示したmain()とyyerror()ルーチンは、lex()の機能そのままの簡単なものである。しかし、ユーザにとって使いやすいコンパイラとするためには、たとえ小さな入力の誤りであっても、少なくとも行番号のレベルで指摘できるものでなければならない。そしてエラー・メッセージとしては、単にSyntax errorと出力するだけでは不十分である。この節では、この問題を解決するための一般的なやり方について述べる。
まず、main()ルーチンから考えてみよう。ファイルの取込み、テキストの置換え、あるいは条件コンパイルの機能を利用するために、Cプリプロセッサを起動できるようになっていることは非常に重要である。Cプリプロセッサはまた、-Cオプションが指定されない限り、C言語のコメントを取り去る。ここでの標準的main()ルーチンは、Cプリプロセッサが理解できるオプションが一つ以上指定されていればプリプロセッサを起動し、-Pあるいは-Eオプションが指定されていれば強制的にプリプロセッサを起動する。
/* * main() -- possibly run C preprocessor before yyparse() */ #include <stdio.h> static usage(name) register char *name; { fputs("usage: ", stderr); fputs(name, stderr); fputs(" [C preprocessor options] [source]\n", stderr); exit(1); } main(argc, argv) int argc; char **argv; { char **argp; int cppflag = 0; for (argp = argv; *++argp && **argp == '-'; ) switch ((*argp)[1]) { default: usage(argv[0]); case 'C': case 'D': case 'E': case 'I': case 'P': case 'U': cppflag = 1; } if (argp[0] && argp[1]) usage(argv[0]); if (*argp && ! freopen(*argp, "r", stdin)) perror(*argp), exit(1); if (cppflag && cpp(argc, argv)) perror("C preprocessor"), exit(1); exit(yyparse()); }
このルーチンはすべての引数を調べている。オプションは必ず−で始まるものとしている。もしCプリプロセッサが理解できるオプションがあれば、後で述べる関数。cpp()を通じ、それらの引数が引き渡されたうえで、プリプロセッサが起動される。オプションの後に、ソース・ファイルとしてオープンされるファイル名が続く。引数の処理が終ると、main()はyyparse()を呼び、その返し値をexit()によってプロセスの終了コードとする。テストとして、このルーチンは非常に便利なものである。コンパイラが完全なものになってくると、このルーチンは他のオプションも取り扱えるように拡張され、誤った引数を与えた場合には、コマンドの使い方の情報を出力するように改良される。
実際にCプリプロセッサを実行するルーチン。cpp()は、多少複雑である。テンポラリ・ファイルを用いないで済むようにするためには、パイプラインを使えるようにすべきである。そのため、yy1ex()は基本的にパイプラインから読み込むようになっている。定義により、yylex()はlex()のマクロとして定義されたinput()ルーチンを呼び、1文字ずつ読み込む。このルーチンは外部変数としてアクセス可能なファイル・ポインタyyinから読み込むものである。yyinは。cpp()において用いられる。
/* * cpp() -- preprocess lex input() through C preprocessor */ #include <stdio.h> #ifndef CPP /* filename of C preprocessor */ # define CPP "/lib/cpp" #endif int cpp(argc, argv) int argc; char **argv; { char **argp, *cmd; extern FILE *yyin; /* for lex input() */ extern FILE *popen(); int i; for (i = 0, argp = argv; *++argp; ) if (**argp == '-' && index("CDEIUP", (*argp)[1])) i += strlen(*argp) + 1; if (! (cmd = (char *)calloc(i + sizeof (CPP), sizeof(char)))) return -1; /* no room */ strcpy(cmd, CPP); for (argp = argv; *++argp; ) if (**argp == '-' && index("CDEIUP", (*argp)[1])) strcat(cmd, " "), strcat(cmd, *argp); if (yyin = popen(cmd, "r")) i = 0; /* all's well */ else i = -1; /* no preprocessor */ cfree(cmd); return i; }
cpp()はまず、Cプリプロセッサが理解できるオプションの数を調べる。そして必要なだけのメモリを得て、それらオプションとともに、Cプリプロセッサを呼ぶためのコマンドを作る。標準ライブラリpopen()を用いることによって、Cプリプロセッサはフィルタとしてyyinに結合される。次にコマンド文字列のためのメモリが解放され、これらの仕事がすべてうまくいった場合には、cpp()は0を返す。
さて、次にエラーの取扱いに目を移そう。まず、位置の情報をわかるようにするメッセージのための標準ヘッダについて考えてみる。ここではソース・ファイルの名前を含む必要がある。Cプリプロセッサが起動された場合はなおさらである。現在の行番号yylinenoは、プリプロセッサが起動されない限り、lexによって正しく処理される。現在あるいは次のtokenはyytext[]にあるが、そのtokenは改行である場合もある。また、ソース・ファイルの一番終りであれば、その内容は空であるかもしれない。どちらの場合も、実際のエラーの行番号はyy1inenoより小さくなる。多くの情報が自動的に生成されるが、それらは注意深く整理する必要がある。
/* * yywhere() -- input position for yyparse() * yymark() -- get information from '# line file' */ #include <stdio.h> extern FILE *yyerfp; /* error stream */ extern char yytext[]; /* current token */ extern int yyleng; /* and its length */ extern int yylineno; /* current input line number */ static char *source; /* current input file name */ yywhere() /* position stamp */ { char colon = 0; /* a flag */ if (source && *source && strcmp(source, "\"\"")) { char *cp = source; int len = strlen(source); if (*cp == '"') ++cp, len -= 2; if (strncmp(cp, "./", 2) == 0) cp += 2, len -= 2; fprintf(yyerfp, "file %.*s", len, cp); colon = 1; } if (yylineno > 0) { if (colon) fputs(", ", yyerfp); fprintf(yyerfp, "line %d", yylineno - (*yytext == '\n' || !*yytext)); colon = 1; } if (*yytext) { register int i; for (i = 0; i < 20; ++i) if (!yytext[i] || yytext[i] == '\n') break; if (i) { if (colon) putc(' ', yyerfp); fprintf(yyerfp, "nerar \"%.*s\"", i, yytext); colon = 1; } } if (colon) fputs(": ", yyerfp); } yymark() /* retrieve from '# digits text' */ { if (source) cfree(source); source = (char *)calloc(yyleng, sizeof(char)); if (source) sscanf(yytext, "# %d %s", &yylineno, source); }
ここではメッセージのために、別のファイル・ポインタyyerfpを定義している。したがって、コンパイラの設計者はメッセージを標準出力(デフォルト)に出力するか、あるいはyyerfpに他のファイル・ポインタを代入して、別のファイルに書くかを選ぶことができる。
yymark()はソース・ファイルと・Cプリプロセッサが付けた位置の印から行の情報を取り出す(2.7節参照)。
すべて必要なものが揃ったら、yywhere()によって作られるメッセージ・ヘッダは次のようになる。
source.c line 10 near "badsymbol";
ここで、badsymbolは普通エラーに続く記号である。
これで,エラーの位置を示す標準のyyerror()ルーチンを書く準備ができたことになる。
#include <stdio.h> FILE *yyerfp = stdout; /* error stream */ yyerror(s) register char *s; { extern int yynerrs; /* total number of errors */ fprintf(yyerfp, "[error %d] ", yynerrs+1); yywhere(); fputs(s, yyerfp); putc('\n', yyerfp); }
(13)yynerrsはyaccによって処理されるカウンタで、yyerror()が呼ばれるたびにインクリメントされる。特に大きなコンパイルを行なった時に、エラー・メッセージに番号付けがされていると有用である。
gccでは、yyerfpの初期化にstdoutを代入することができなかった。そこで、yyerrorのはじめにyyerfp = stdout;をセットすることにした。
本来は、main.cでセットするのがよいだろう。
この段階で、やっとパーサのテストを行なうことができるようになる。残念ながら、正しい入力ファイルをパーサに与えた場合は、まったく何も出力されない。もし入力ファイルが正しくなければ、いくつかのエラー・メッセージが得られるであろう。逆に、正しい入力ファイルを与えたにもかかわらず、エラー・メッセージが出力されたなら、そのパーサは誤っていることになる。この場合、yyparse()がなぜエラー・メッセージを出力するルーチンを呼んだのかを考えなくてはならない。
2.6節で述べたテクニックによって、構文解析プログラムが間違っていないことを確かめることができる。つまりyyparse()は入力ファイルにある記号を確かに受け取っていることがわかる。このことを確かめたなら、yaccの持つデバッグの機能を使うことができる。パーサy.tab.cをコンパイルする時に、記号YYDEBUGを定義すると、
cc -DYYDEBUG y.tab.c 1ex.yy.c main.c yyerror.c -11
整数変数yydebugを0でない値に設定することによって、関数yyparse()はトレース・オプションを含む。yydebugは外部変数で、たとえばadbによってもセットすることができる。
adb -w a.out yydebug?w 1 $q
ここで、1.4節で示した簡単な式の文法を多少変更したものを使った場合のトレースの結果を示す。初歩的な構文解析プログラムは,次のようになる。
%{
#include "y.tab.h"
%}
%%
[a-z]+ return IDENTIFIER;
[ \t\n] ;
. return yytext[0];
初めのバージョンの文法では、一は明確な規則として左優先となるように定義される。
%token IDENTIFIER
%left '-'
%%
expression
: expression '-' expression
| IDENTIFIER
%%
main()
{
#ifdef YYDEBUG
extern int yydebug;
yydebug = 1;
#endif
printf("yyparse() == %d\n", yyparse());
}
lexのように,yaccの入力ファイルも%%で始まる三番目の部分を持つ場合があるが、この部分はy.tab.cにコピーされる。もしyydebugが存在するならば、そのセットを行なうmain()ルーチンが存在する。わかりやすくするために、yyparse()の返し値が示されるようになっている。
yaccはパーサのために、次のようなy.outputファイルを作成する。
state 0 $accept : _expression $end IDENFIFIER shift 2 . error expression goto 1 state 1 $accept : expression_$end expression : expression_- expression $end accept - shift 3 . error state 3 expression : expression -_expression IDENTIFIER shift 2 . error expression goto 4 state 4 expression : expression_- expression expression : expression - expression_ (1) . reduce 1
統計のための情報は省いてある。
lexおよびyaccへの入力が、それぞれファイルexp.1とexp.yにあるとする。パーサを作成し、正しい入力を与えて実行してみよう。
yacc -dv exp.y lex exp.l cc -DYYDEBUG y.tab.c lex.yy.c -ll -o exp exp a - b - c ^D
y.outputとともに、トレース情報2によって入力ファイルがどのように処理されたかが示される。
[yydebug] push state 0 [yydebug] reading IDENTIFIER [yydebug] push state 2 [yydebug] reduce by (2), uncover 0 [yydebug] push state 1 [yydebug] reading '-' [yydebug] push state 3 [yydebug] reading IDENTIFIER [yydebug] push state 2 [yydebug] reduce by (2), uncover 3 [yydebug] push state 4 [yydebug] reduce by (1), uncover 0 [yydebug] push state 1 [yydebug] reading '-' [yydebug] push state 3 [yydebug] reading IDENTIFIER [yydebug] push state 2 [yydebug] reduce by (2), uncover 3 [yydebug] push state 4 [yydebug] reduce by (1), uncover 0 [yydebug] push state 1 [yydebug] reading [end of file] yyparse() == 0
これを見ると、
expression : expression '-' expression
が、二つ目の-を読む前にreduceされたことが簡単にわかる。認識は成功し、yyparse()は関数の値として0を返す。
%token IDENTIFIER
%right '-'
%%
expression
: expression '-' expression
| IDENTIFIER
これと反対に、-を右優先先とする明確な規則を持った文法を考えてみよう。
state 4
expression : expression_- expression
expression : expression - expression (1)
- shift 3
. reduce 1
ここで、-が右優先となる。一番右の-のフレーズが最初にリデュースされなければならず、そしてその結果として、すべての-の演算子がyaccのスタックにプッシュされる。このyyparse()で用いられるアルゴリズムでは、左再帰の規則と左優先の演算子で必要とするより、スタックの領域は少なくて済む。
前の例と同じ入力を与えると、次のようなトレースが得られる。
[yydebug] push state 0 [yydebug] reading IDENTIFIER [yydebug] push state 2 [yydebug] reduce by (2), uncover 0 [yydebug] push state 1 [yydebug] reading '-' [yydebug] push state 3 [yydebug] reading IDENTIFIER [yydebug] push state 2 [yydebug] reduce by (2), uncover 3 [yydebug] push state 4 [yydebug] reading '-' [yydebug] push state 3 [yydebug] reading IDENTIFIER [yydebug] push state 2 [yydebug] reduce by (2), uncover 3 [yydebug] push state 4 [yydebug] reading [end of file] [yydebug] reduce by (1), uncover 3 [yydebug] push state 4 [yydebug] reduce by (1), uncover 0 [yydebug] push state 1 yyparse) == 0
この結果、ファイルが終了した後に(end of fileの後)フォーミュレーション(1)に関する二つのリダクションが行なわれているのがわかる。
トレースは、たとえば次のような誤った入力を与えた場合に、より有効となる。
a - -
左優先の場合、出力は次のようになる。
[yydebug] push state 0 [yydebug] reading IDENTIFIER [yydebug] push state 2 [yydebug] reduce by (2), uncover 0 [yydebug] push state 1 [yydebug] reading '-' [yydebug] push state 3 [yydebug] reading '-' [yydebug] push state 3 [yydebug] reading '-' [error 1] line 1 near "-":expecting: IDENTIFIER [yydebug] recovery pops 3, uncovers 1 [yydebug] recovery pops 1, uncovers 0 [yydebug] recovery pops 0, stack is empty yyparse() == 1
y.outputを見ると、state3ではIDENTIFIERだけがパーサに受け入れられることがわかる。これはまた、出力されたエラー・メッセージからもわかる。また、トレースによれば、どのようにstate3に入ったが、そして入力のエラーをひとたび発見したら、yyparse()はそのスタックをすべて消し去ってしまうことを読み取ることができる。この例では値1が返されている。エラー・リカバリについては、第4章でさらに詳しく述べる。
最後に、文法を次のように変えてみよう。
%token IDENTIFIER
%nonassoc '-'
%%
expression
: expression '-' expression
| IDENTIFIER
ここでは、-は他と関連しない(nonaSSoC)ものとして記述されているため、引き算の記述は誤りとなる。y.outputでは、遷移行列におけるState4に関する変更は、次のようになる。
state 4
expression : expression_- expression
expression : expression - expression_ (1)
- error
. reduce 1
次の入力、
a - b - c
のトレースを行なうと、この文法は論埋的におかしなものであることがわかる。
[yydebug] push state 0 [yydebug] reading IDENTIFIER [yydebug] push state 2 [yydebug] reduce by (2), uncover 0 [yydebug] push state 1 [yydebug] reading '-' [yydebug] push state 3 [yydebug] reading IDENTIFIER [yydebug] push state 2 [yydebug] reduce by (2), uncover 3 [yydebug] push state 4 [yydebug] reading '-' [error 1] line 1 near "-": syntax error [yydebug] recovery pops 4, uncovers 3 [yydebug] recovery pops 3, uncovers 1 [yydebug] recovery pops 1, uncovers 0 [yydebug] recovery pops 0, stack is empty yyparse() == 1
state 2ヘシフトし,そのIDENTIFIERをexpressionとしてリデュースする。そして、state 0に戻り、expressionを受け入れ、state 1に移る。-bは受け入れられ、state 1からstate 3、state 2にシフトされる。ここでIDENTIFIER bはもう一度expressionとしてリデュースされる。しかしスタックにstate 3を見つけ、expressionとともにstate 4に移ることになる。結局、-に対して、遷移行列におけるerrorの演算が行なわれることになる。
この例で文法の誤りを探すとすると、なぜ-がstate 4にたどり着くことができなかったかを考えなければならない。state 1とstate 4とを比べると、次のコンブィグレーション、
expression : expression_-expression
は、-に対して二つの異なった遷移行列のエントリを与えていることが判明する。これは、おかしな規則が指定された時にのみ可能で、文法製作者の誤りであることになる。
この例はあまり明瞭なものではないかもしれないが、デバッグのテクニックは明瞭である。ここで示した例を見れば、y.outputを用いてyydebugのトレースを行なうことにより、誤った点を見つけ出すことは容易であることがわかる。しかし、最後の例で行なったように、おかしな規則によって引き起こされる悪影響を取り除くことは、トレースとデバッグにおいてもっとも困難な仕事である場合が多い。
IdentifierとConstantは終端記号にクラス分けされる。バーサは文の認識のような場合においてクラスに関与するだけであるが、さらに処理を行なうと、終端記号の実際の値も必要となってくる。ここでは、変数を使うことのできない簡単な電卓を作ることを考えてみよう。
/* * desk calculator */ %token Constant %left '+' '-' %left '*' '/' %% line : /* empty */ | line expression '\n' { printf("%d\n", $2); } expression : expression '+' expression { $$ = $1 + $3; } | expression '-' expression { $$ = $1 - $3; } | expression '*' expression { $$ = $1 * $3; } | expression '/' expression { $$ = $1 / $3; } | '(' expression ')' { $$ = $2; } | Constant /* $$ = $1; */
中カッコ({と})でくくられた部分は、フォーミュレーションがどのように変換されるかを示すコメントである。以下に、記述とその読み方の例を示す。
expression : expression '+' expression
{ $$ = $1 + $3 }
“もし十で結合された二つのexpressionを見つけたなら、その値を加えなければならない。そしてその値は、リデュースされたexpresSionの値となる。”
expression : '(' expression ')'
{ $$ = $2; }
“カッコでくくられたexpressionを見つけたなら、リデュースされたexpressionの値は、そのフォーミュレーションにおける二番目のシンボルの値となる。”
expression : Constant /* $$ = $1; */
“Constantを見つけたなら、リデュースされたexpressionの値は、そのフォーミュレーションにおける一番目の記号の値となる。すなわちConstantの値そのものである。”(15)
line : line expression '\n'
{ printf("%d\n", $2 );}
“完全な1ineを見つけたなら、そのフォーミュレーションにおける二番目の値をプリントしなければならない。”
実際、中カッコは単なるコメント以上の意味を持っている。yaccではそれぞれのフォーミュレーションの後に、中カッコでくくられたC言語の文をアクションとして指定することができる。指定されたアクションは、フォーミュレーションがリデュースされた時に実行される。
yypase()は値のスタックと、3.1節で示された状態スタックとを同時に取り扱う。記号が受け入れられた場合、すなわち、shiftあるいはgotoの操作の時に現在の状態が状態スタックに積まれると、対応する値が値スタックに積まれる。
終端記号が受け入れられて、shiftの操作でスタックに積まれる値は、yaccによって定義される整数の広域変数であるyylvalの値となる。yylvalは終端記号のための構文解析プログラムによりセットされる。この例では、Constantの実際の値がそこになくてはならない。
%{
/*
* lexical analyzer for desk calclulator
*/
#include "y.tab.h"
extern int yylval;
%}
%%
[0-9]+ { yylval = atoi(yytext); return Constant; }
[ \t]+ ;
\n |
. return yytext[0];
ライブラリ関数atoi()は、数字の文字列から整数の値を計算するもので,この値はConstantの実際の値としてyylvalに記録される。
この例が示すように、アクションでは普通リデュースされようとしているフォーミュレーションのための記号が受け入れられる時に、値スタック中の値にアクセスできる必要がある。フクション中の$iの記述は、値スタック上にあるフォーミュレーション中のi番目の記号を示しており、また、$$はyyval、すなわち、reduceの後のgotoの操作によって非終端記号が受け入れられる時に値スタックにプッシュされることになる値を示している。
次のアクション、
{ $$ = $1; }
がまず最初に与えられる。これは、“フォーミュレーション中の一最初の記号の値スタックのエントリが、フォーミュレーションがリデュースされる非終端記号の値スタックのエントリになる”という状態を意味している。
ここで示した電卓は、きちんと機能するはずである。それぞれのConstantに対し、構文解析はyyparse()が値スターソクにセットした実際の値をyylvalに与える。次のようなフォーミュレーション、
expression : expression '-' expresion
がリデュースされたなら、対応するアクション、
{ $$ = $1 - $3; }
によって、リデュースの後に値スタックにプッシュされる値、すなわちその差が計算される。そして初めに示されている関数printf()によって、電卓に入力された“式”であるlineの値が出力されることになる。
yylval、yyval、そして値スタックは、非常に多くの種類の情報を保持するために用いられる。特に指定しない限り,値スタックはintをその要素とする。ここに示した電卓のような例では、doub1eを要素とするほうが良いかもしれない。また、コンパイラにおいては、yylvalはそれぞれの“大きな”終端記号のための記号テーブルのエントリのポインタを持つ方が望ましい。しかし残念なことに、doubleの値や、場合によってはポインタでさえも、int変数にストアしたり、int変数から取り出したりすることができない。
パーサによって取り扱われる値スタックは、yaccの仕様の範囲において型を与えることができる。このセクションでは、yaCC自身とまったく透過となるような値スタックに対する型の与え方について述べる。拡張したセマンディックスのチェックをyaccが必要とするような、さらに手の込んだ型を与える方法については5.4節で述べる。
yylval、yyval、そして値スタックは、バーサにおいてYYSTYPEという型となるように定義される。YYSTYPE自身は、yaccに対する記述の最初の部分で特に指定されない限り、Cプリプロセッサによってintとして定義される。この定義がyaccに対して透過であるようにするためには、次のようにしなくてはならない。
%{
#define YYSTYPE double
%}
%%
/* grammar, etc. */
lexでの仕様と同様に、yaccのための記述の%{と%}でくくられた始めの部分は、作られたパーサにコピーされる。コピーされた部分は、出力ファイルの始めの部分に置かれるため、yaccによって与えられるデフォルトの定義は書き換えられることになる。
値スタックをdoubleとする場合には、電卓のための構文解析プログラムを多少変更しなくてはならない。yylvalもdoubleとなるので、数字の文字列の変換部分を変更する必要が生じる。
%{
/*
* lexical analyzer for 'double' desk calculator
*/
#include "y.tab.h"
extern double yylval, atof();
%}
digits ([0-9]+)
pt "."
sign [+-]?
exponent ([eE]{sign}{digits})
%%
{digits}({pt}{digits}?)?{exponent}? |
{digits}?{pt}{digits}{exponent}? {
yylval = atof(yyext);
return Constants;
}
[ \t]+ ;
\n |
. return yytext[0];
この例は、数字、小数点、数字、場合によっては符号付きの指数で表わされる浮動小数の定数が、lexを使ってどのように認識され、またライブラリ関数atofOによってどのように変換されるかを示している。
値スタックに型を与えるこのテクニックは、非常に使いやすく、さらに文法の変更を一切必要としないが、一つ問題を抱えている。YYSTYPEは定義された名前である。一方、値スタックとしての型は一つの型の名前として、すなわち、一つの識別子あるいは一つの構造体として与えられなくてはならない。しかしながら、YYSTYPEに対するテキストの置換えはポインタであってはならない。そのような指定をする場合には、代わりにtypedefを用いて一つの識別子としてやらなくてはならない。typedefによって与えられた識別子を用いることによって、初めてYYSTYPEの置換えが可能となる。
typedef char *CHAR_PTR; #define YYSTYPE CHAR_PTR
ここでは、型の名前として使われている識別子はCHAR-PTRとなっている。このテクニックは美しいものとは言えないかもしれないが、
#define YYSTYPE char *
という定義がyaccparによって正しく認識されないため、どうしても必要となる。
それでは、sampleCのインデント(段付け)を行なう整形プログラムを考えてみよう。まず、現在の文法を少し変更する必要が出てくる。つまり、終端記号がプリントされるようにするための終端記号に対するアクションが必要となる。このような作業は、もちろん構文解析のプログラムだけで可能であるが、ある種の文をシンタックスや文脈を踏まえた上で正しくインデントすることはできない。構文解析プログラムと文法におけるアクションの両方で出力を行なうのは、良い方法とは言えない。なぜなら、パーサは終端記号を一っ先読みするために、構文解析プログラムを呼ぶことができるが、必ず行なわれるわけではないからである。
いかなるものを作るべきかを理解するために、次のsampleCのプログラムについて考えてみよう。このプログラムは意味のある実行を行なうものではないが、シンタックス的には正しい。ただ、その記述が美しくないだけである。
/* * formatting demonstration */ main(a,b) int a,b; { a=b; {a;b;} if (a==b) {a;b;} if (a==b+1) a; else b; while (a==b) {a; break; continue;} return; ; } int f() {int x;int y; return nothing; }
インデントは、個人の趣味によってそのやり方が異なるが、ここでの整形プログラムは、次のような出力を行うものとする。
main(a, b) int a, b; { a = b; { a; b; } if (a == b) { a; b; } if (a == b + 1) a; else b; while (a == b) { a; break; continue; } return; ; } int f() { int x; int y; return nothing; }
いくつかの終端記号、特に中カッコとelseはインデントを制御しているため、特別な扱いをしてやらねぱならない。これは文法におけるアクション間で、文脈に関連した情報をやりとりしなくてはならないことの良い例となっている。すなわち、elseはインデントを発生させるが、ここでのインデントのスタイルでは、直後にくる複文のための中カッコは、行の幅を節約するために、{と}の双方とも、elseと同じインデントのレベルになくてはならないようになっている。それゆえ、必要な情報を静的変数を通じてやりとりすることになる。
整形のためのアクションは、いくつかの二一モニックを使って指定され、fmt.hにおいて定義される。fmt.hは、yaccの値スタックのための型の情報も含んでいる。
/* * formatting call mnemonic parameters */ #define IN 1 /* margin inward */ #define EX (-1) /* margin outward */ #define AT 0 /* margin as is */ /* * yacc value stack type (pass texts!) */ typedef char * CHAR_PTR; #define YYSTYPE CHAR_PTR;
整形プログラムは、すべての出力を行なう基本ルーチンである。out()を用いる。out()ルーチンでは出力行の文字数を調べることもできるし、また必要に従って行を加えたり、ぺ一ジ替えを行なったりすることもできる。以下のいくつかの基本ルーチンを含むファイルをfmt.cとする。
/* * sample c -- utilties for formatter */ #include <stdio.h> #include "fmt.h" /* * rudimentary sybol table routine: * save text of every symbol. */ s_lookup(yylex) int yylex; /* Constant or Identifier */ { extern YYSTYPE yylval; /* semantic value for parser */ extern char yytex[]; /* text value of sybol */ extern char * strsave(); yylval = strsave(yytext); } /* * formatter calls: * * at(AT) no-op * at(IN) set margin inward * at(EX) set margin outward * nl(delta) emit newline, at(delta) * cond(IN) nl(IN) * cond(EX) if directly preceded by cond(IN): at(EX) * uncond(AT) nl(AT) * uncond(EX) unless just after uncond(AT): at(EX) * out(s) emit string s * * Margin settings take effect just prior to first out(s) on * the new line. 'cond' calls fiddle with braces and else. */ static int lmargin = 0; /* left margin, in tabs */ static int atmargin = 1; /* set: we are at left margin */ static int condflag = 0; /* managed by cond(), = 0 by out() */ static int uncdflag = 0; /* managed by uncond(), = 0 by out() */ at(delta) int delta; { lmargin += delta; } cond(delta) int delta; { switch (delta) { case AT: ++uncdflag; nl(AT); break; case EX: if (! uncdflag) at(EX); } } nl(delta) int delta; { at(delta); putchar('\n'); atmargin = 1; } out(s) char *s; { if (atmargin) { register int i; for (i = 0; i < lmargin; i++) putchar('\t'); atmargin = 0; } fputs(s, stdout); condflag = uncdflag = 0; }
strsave()は[Ker78b]に示されている便利な関数で、引数として渡された文字列を動的に保存するルーチンである(付録のA.3節参照)。このルーチンは整形プログラムのための記号テーブルのためには十分なものである.
終端記号プリントのためのアクションと、そのための終端記号に対する規則を加えたことを除けば、yaccへの入力は基本的に変わっていない。そのため、ここでは変更や拡張が必要であった部分のみ示す。